Training Open-Source Large Language Models for Cybersecurity
07:19:2024
BY Bradley Hartlove
Large language models (LLMs) continue to revolutionize the field of natural language processing (NLP). With the success of platforms such as OpenAI’s ChatGPT and Google’s Gemini, professionals in nearly every industry leverage these powerful models to augment their workflows. With cybersecurity encompassing such a vast array of disciplines and technologies, ample space exists for these NLP technologies to assist developers, engineers, and operators. In this blog, we’ll examine how SealingTech leads the charge in helping our customers do just that via in-house training on cutting edge open-source models.
Large language models: an overview
Most users associate LLMs with platforms like ChatGPT that work in an autoregressive fashion. In other words, a trained model predicts the next piece of text given based on the previous input. Once that new text generates, it’s added back to the original input, and the whole process repeats until the end of the response is reached. To visualize, see below diagram:
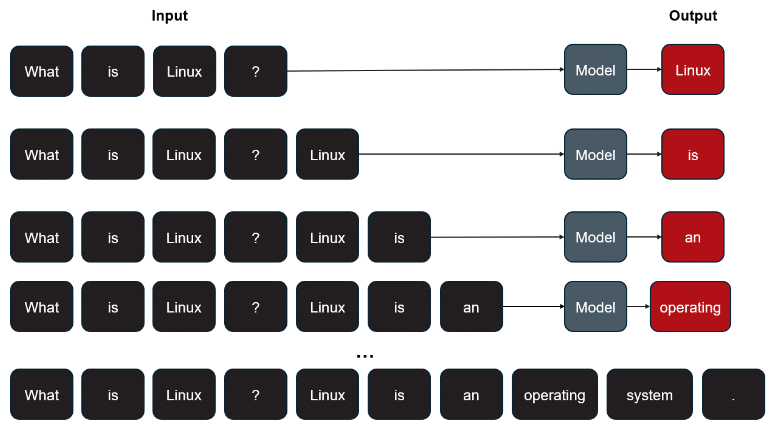
Figure 1: Autoregressive Model Example
As you can see, a user sends a question or query to the model and it streams back a response word by word, or more accurately, a token. These tokens represent predefined words, letters, chunks of words, numbers, etc., defined by the model’s authors.
Off-the-shelf LLMs as seen above allow for users to perform simple Q&A tasks, sentiment analysis, and even code requests. However, as more companies began to release open-source models such as Meta’s Llama or Mistral’s Mistral, research to determine how else these models can be leveraged has rapidly expanded.
From RAG to Agents
One of the most well-known and functionally impactful use cases for models involved retrieval augmented generation (RAG). In this scenario, documents such as user manuals, books, and web pages were chunked up and stored in a database via vectors. These vectors perform as simply lists of numbers that store the semantic meaning of the text that they correlate to. The thinking here is that similar text will be “closer together”. In doing so, a user’s queries will convert into vectors and the most similar text stored in the database extracted, essentially providing the model with additional information to answer queries. In other words, users can supply models with internal, private, or lesser-known information through documents that the model can then reference to enhance and customize responses. This resulted in a valuable discovery as it allowed for documentation to be included that was previously unavailable to the model at time of training.
While this approach garnered a lot of well-deserved attention and research, it fell short for other use cases. What if the information a user requests isn’t in documentation but stored in a database? Or the information is a specific configuration on a system on their network? This is where the idea of agents come into the fold.
Employing agents and critical finetuning
In broad terms, an agent is a type of LLM application where the model interacts with an environment. For example, it calls code on a calculator tool when arithmetic needs to be performed. In the cybersecurity world, this translates into running a system scan or querying a security event and incident management (SEIM) for information. Our expert team at SealingTech leads in the development of LLM agents to address these use cases for our customers.
In a typical LLM application, if a user sends the query: What ports remain open on 1.2.3.4?, the model will likely reply: While I don’t have access to real-time information, here are some steps you can take . . .
With the agents SealingTech has developed, this now becomes a prompt to a custom-built agent that writes an Nmap command to check for the ports open on 1.2.3.4, then returns the results to the user resulting in a more precise and organic response.
Beyond checking for ports, another capability in development at SealingTech entails interacting with Elasticsearch data via natural language. Like the query example above, a user can ask an agent: Do I have any HTTP traffic to the domain bad.domain.com? The model will then generate the code to search Elasticsearch for this information. In both agents, user confirmation is required before any code can be executed.
However, even the most cutting edge open-source LLMs being released to date do not have the knowledge required to support these agents. Consider the number of unique fields in Elasticsearch (in a Security Onion deployment, this is in the scale of thousands), or the dozens of parameters available to a command such as Nmap and how they can work together. Open-source models are typically trained on general knowledge. While they will pick up coding skills and can write some correct code and commands, most fail to deliver more than a surface level of understanding.
To work around this, SealingTech custom trains multiple models using a technique called low-rank adaptation or LoRA. At a high level, this technique allows developers to train these models which typically have billions of parameters (think of a parameter as simply a number the model that can be changed) with a far-lower GPU footprint. By adding in a small number of new parameters to the model and “freezing” the rest, developers can take a process that would take upwards of days and significant GPU power and perform the training in the span of a couple hours on a fraction of the compute space.
SealingTech’s team continues to create datasets around agents to query Elasticsearch and craft Nmap commands. We’re actively working on extending the robustness of these datasets to further improve the models over time. Results thus far have proven that models can accurately write code and create intelligent commands given proper training and prompting techniques. In the future, these agents will be in the hands of our customers, giving them the ability to simplify their workflows and take time-consuming or complex tasks, and turn them into straightforward, natural language questions.
Interested in learning more? Contact our team today.
Related Articles
The Call for Explainable AI
Enhancing Network Visibility with Machine Learning Artificial intelligence (AI) and machine learning are transforming business processes across industries. For many organizations, data has become their most valuable asset. The ability…
Unsupervised Learning for Cybersecurity
Dashboards and automated alerts remain well-established fundamental components of nearly every cybersecurity team’s toolbelt. Peel back the layers of a network monitoring tool suite, and you’ll discover that every team…
Operator X: An Intern Experience
SealingTech’s exciting new innovation Operator X is a chat interface built to assist cyber operators by bridging knowledge gaps via the use of cutting-edge generative AI tools and techniques. It…
Could your news use a jolt?
Find out what’s happening across the cyber landscape every month with The Lightning Report.
Be privy to the latest trends and evolutions, along with strategies to safeguard your government agency or enterprise from cyber threats. Subscribe now.